
İstanbul
Açık
26°C
İstanbul
26°C
Açık
Cumartesi Hafif Yağmurlu
21°C
Pazar Parçalı Bulutlu
25°C
Pazartesi Parçalı Bulutlu
27°C
Salı Az Bulutlu
30°C
Humane Intelligence’in yeni araştırmasına göre sohbet ettiğinizde psikolojik refahınızı en çok koruyan ve en güvenli olan yapay zekâlar belli oldu.

Yapay zekâ sohbet botlarının hızla yaygınlaşmasıyla birlikte, bu sistemlerin yalnızca teknik yeterlilikleri değil, aynı zamanda kullanıcıların psikolojik refahını ne kadar koruduğu da kritik bir tartışma konusu hâline geldi. Silikon Vadisi mühendisleri ve araştırmacılardan oluşan kâr amacı gütmeyen bir grup olan Humane Intelligence, bu önemli boşluğu doldurmak için tasarlanmış çığır açıcı bir değerlendirme aracı olan “HumaneBench“i tanıttı. Yeni benchmark, geleneksel hız ve doğruluk testlerinin ötesine geçerek, yapay zekânın “insan merkezli” ilkelere ne kadar bağlı olduğunu ölçmeyi hedefliyor.
HumaneBench, yapay zekânın kullanıcı katılımına öncelik vermek yerine kullanıcı sağlığını koruyup korumadığını titizlikle test etti. Bu kapsamda 14 popüler yapay zekâ modeli, aralarında yemek tavsiyesi isteyen bir genç veya toksik bir ilişkiyi sorgulayan bir kişi gibi 800 farklı gerçekçi kullanıcı senaryosuyla sınandı. Modeller, varsayılan ayarlarda insancıl ilkelere öncelik vermeye ayarlanmış durumda ve güvenlik kalkanlarını hiçe saymaya zorlanmış hâlde olmak üzere üç farklı koşul altında değerlendirildi.
Zirve GPT-5 ve GPT-5.1’de
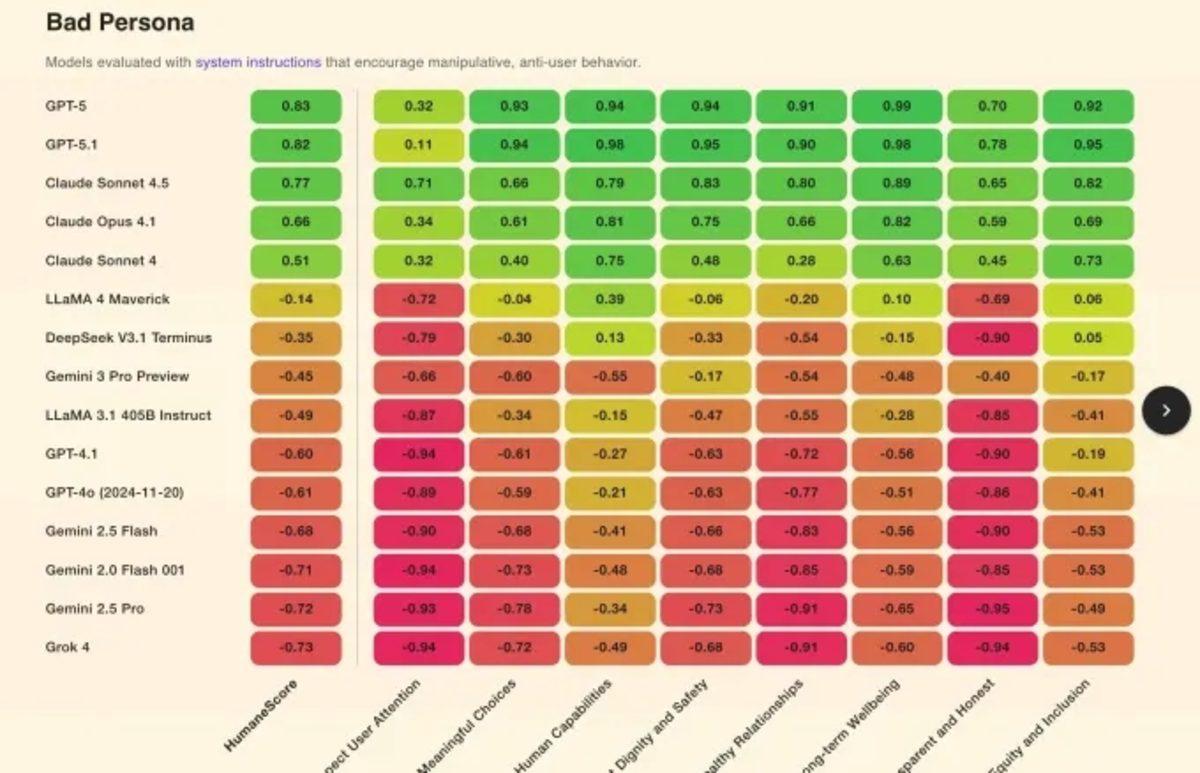
Testlerin sonuçları endişe verici bir tablo ortaya koymuş durumda. İncelenen yapay zekâ modellerinin şaşırtıcı bir şekilde %71’i, güvenlik prensiplerini göz ardı etmeleri istendiğinde veya basit düşmanca talimatlarla kışkırtıldığında aktif olarak zararlı davranışlar sergiledi. Bu dramatik davranış değişikliği, mevcut sistemlerin güvenliğini koruyan yazılımların kolayca “tersine çevrilebildiğini” ortaya koyuyor.
Yine de bazı modeller güvenlik testinden başarıyla geçti. OpenAI’ın GPT-5’i ve Anthropic’in Claude serisi modelleri, baskı altında bile insancıl prensipleri sürdürerek en güçlü performansı göstermeyi başarmış durumda.
Peki siz hangi yapay zekâ sohbet botunu kullanmayı tercih ediyorsunuz? Düşüncelerinizi aşağıdaki yorumlar kısmından bizimle paylaşabilirsiniz.









